transformer 模型随笔
随便记录自己想到的问题,自问自答,后续会整理整个transformer 模型的原理及其复现 问题: 在transformer中每个功能层添加add & norm 层的原因 batch norm, layer norm 原理及其区别,以及使用场景
Unigram Language Model (ULM)
Ulm 分词算法(通常指 ULM, Unsupervised Language Modeling 分词,或与 SentencePiece 中的 Unigram 语言模型算法高度相关)是一种基于统计概率的子词(Subword)分词算法。 与传统的结巴分词(基于词典)或简单的 BPE(基于频次合并)不同,ULM 的核心逻辑是:从一个巨大的候选词表出发,通过概率模型不断“剔除”对整体语言模型贡献度低的词,直到达到目标词表大小。 1. 原理详解ULM 算法建立在假设:一个句子 $S$ 的分词序列 $x = (x_1, x_2, …, x_n)$ 的概率等于各子词概率的乘积: $$ P(x) = \prod_{i=1}^{n} P(x_i)$$ 核心步骤: 初始化:生成一个非常大的初始词表(例如:所有出现的字符 + 频繁出现的子串)。 期望最大化 (EM 训练): E-Step:在当前词表下,利用维特比算法 (Viterbi) 找到语料库中最优的分词路径。 M-Step:根据分词结果更新词表中每个词的出现概率 $P(x_i)$。 计算损失 (Loss):...
WordPiece 分词算法原理
WordPiece 分词算法 Google BERT 的核心分词技术 简介WordPiece 是 Google 在 2016 年为了解决神经机器翻译问题提出的分词算法,后来因为成为了 BERT 的默认分词方案而彻底走红。自此之后,很多基于 BERT 的 Transformer 模型都复用了这种方法,比如 DistilBERT、MobileBERT、Funnel Transformers 和 MPNET。 初识 WordPiece如果说 BPE 是单纯的统计学家(看数量),那么 WordPiece 就像是一个概率学家(看概率)。 核心思想 WordPiece 的核心目标:最大化训练数据的似然概率 与 BPE 的贪心合并策略不同,WordPiece 采用概率模型来选择如何合并子词。 WordPiece vs BPE:核心区别 维度 BPE WordPiece 合并逻辑 统计最频繁的字节对 最大化训练数据似然概率 选择标准 频率最高 最大化似然增量(PMI) 子词标记 词首加 Ġ (GPT 风格) 非词首加 ## 分词策略 贪心匹配 最长匹配 应用模...
分词算法BPE
Byte Pair Encoding (BPE) 概念及其原理 简介Byte Pair Encoding (BPE) 是 NLP 中最重要的编码方式之一,它的有效性已被 GPT-2、RoBERTa、XLM、FlauBERT 等强大的语言模型所证实。 初识 BPEBPE 是一种简单的数据压缩算法,它在 1994 年发表的文章”A New Algorithm for Data Compression”中被首次提出。 核心思想 BPE 每一步都将最常见的一对相邻数据单位替换为该数据中没有出现过的一个新单位,反复迭代直到满足停止条件。 压缩示例假设我们有需要编码(压缩)的数据 aaabdaaabac。 相邻字节对 aa 最常出现,用新字节 Z 替换 结果:ZabdZabac,其中 Z = aa 下一个常见字节对是 ab,用 Y 替换 结果:ZYdZYac,其中 Z = aa,Y = ab 继续递归编码 ZY 为 X 最终结果:XdXac,其中 X = ZY,Y = ab,Z = aa 无法进一步压缩,因为没有重复出现的字节对 解码:反向执行以上过程即可还...

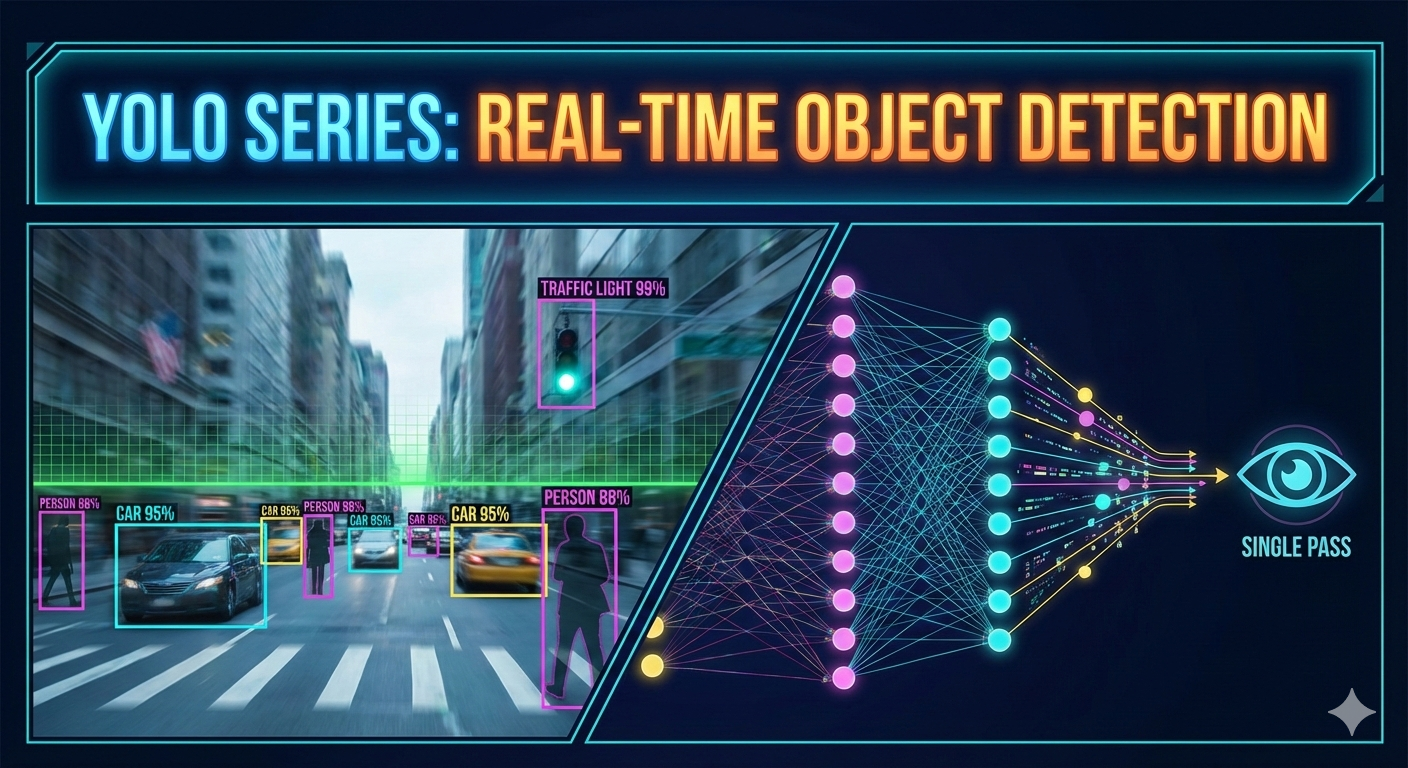
寻根溯源:我的 YOLO 全系列深度解析之旅 (开篇)
寻根溯源:我的 YOLO 全系列深度解析之旅 (开篇)0. 前言:为什么要写这个系列?在计算机视觉(CV)的江湖里,YOLO (You Only Look Once) 是一个绕不开的名字。从 2015 年 Redmon 提出 v1 版本至今,YOLO 系列已经走过了近十个年头,演进到了如今的 v11。 作为一名算法从业者,我几乎每天都在和各种版本的 YOLO 打交道:调参、部署、优化。但在高强度的工作节奏下,我发现自己陷入了一个**“熟练的陌生人”**误区: 对抗遗忘: 算法的演进非常细碎。从 Anchor-based 到 Anchor-free,从简单的 IoU 到复杂的 $CIoU$、$DIoU$ 损失函数,如果不系统整理,很多细节(如正负样本匹配策略的改变)很容易在脑海中变得模糊。 构建底层逻辑: 仅仅跑通 train.py 是远远不够的。为了在面试中对答如流,也为了在实际业务中能根据场景选择最合适的版本,我需要从底层原理出发,理解每一代 YOLO “为什么要这么改”。 职业背书: 博客是最好的技术名片。通过深度解析,我希望向同行和面试官展示:我不仅能通过工具解决问题,更...
Hello World
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub. Quick StartCreate a new post1$ hexo new "My New Post" More info: Writing Run server1$ hexo server More info: Server Generate static files1$ hexo generate More info: Generating Deploy to remote sites1$ hexo deploy More info: Deployment
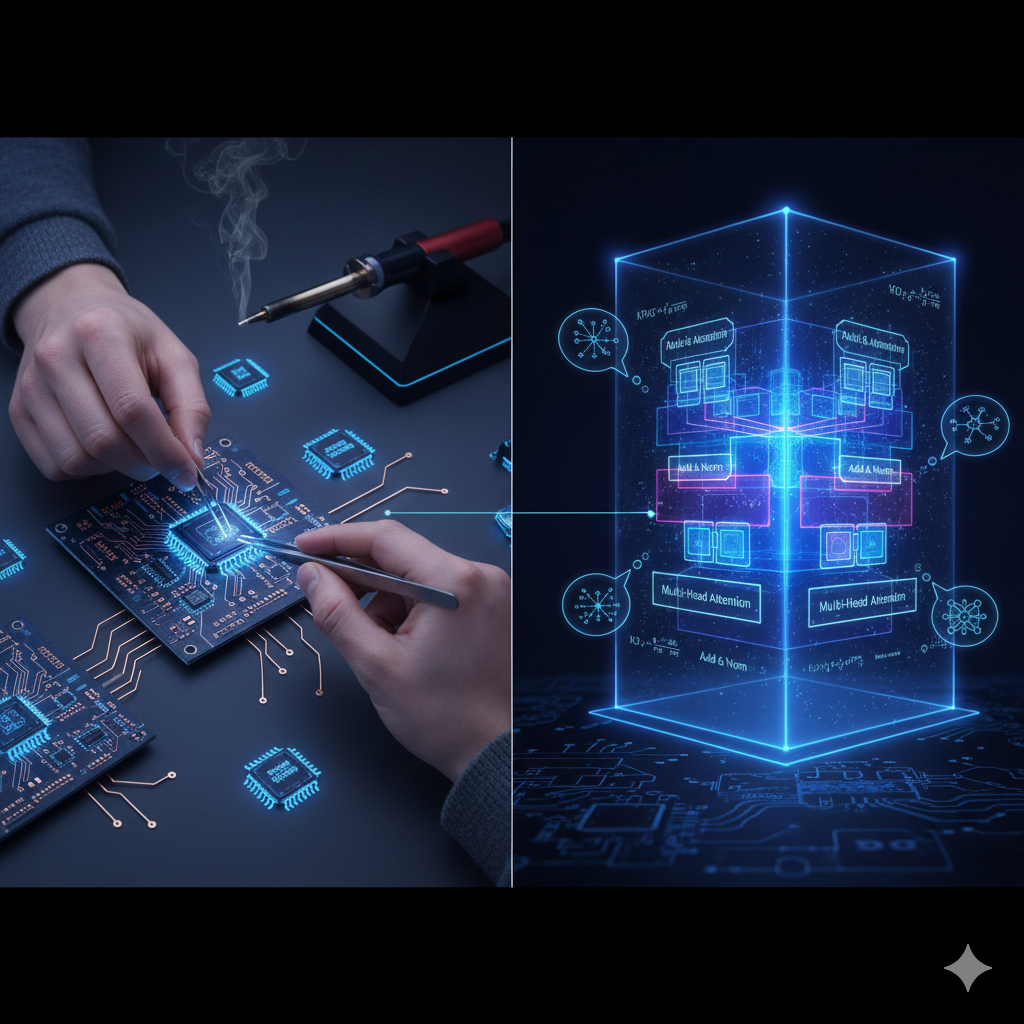
transformer 手搓过程及思考
transformer 手搓过程及思考1. 前言最近在研究transformer,发现网上很多教程都是直接给出代码,没有详细讲解,导致自己看了很久还是一头雾水,因此决定自己动手实现一个transformer,加深对transformer的理解。 2. transformer 基本结构transformer的基本结构如下: transformer由encoder和decoder两部分组成,encoder和decoder都是由多个相同的层堆叠而成,每个层由多头自注意力机制和前馈神经网络组成。 参考 Attention Is All You Need https://github.com/harvardnlp/annotated-transformer